
|
Prompt injection is the injection attack we can't actually fix.
Injection attacks💉 work by tricking a program to execute parts of malicious input data as if they were program code. In SQL for example, your code and text data are separated via apostrophes ('). Code is executed deterministically, while data is just payload. If the attacker can craft malicious input data to circumvent this separation (e.g. by having apostrophes in the input data), the system may execute data from the attacker as if it was code → they 'hack' the system.
Solution: Ensure your separation is robust and accounts for malicious input. (For SQLi: either ensure input cannot have apostrophes or escape them properly, use prepared statements, etc.)
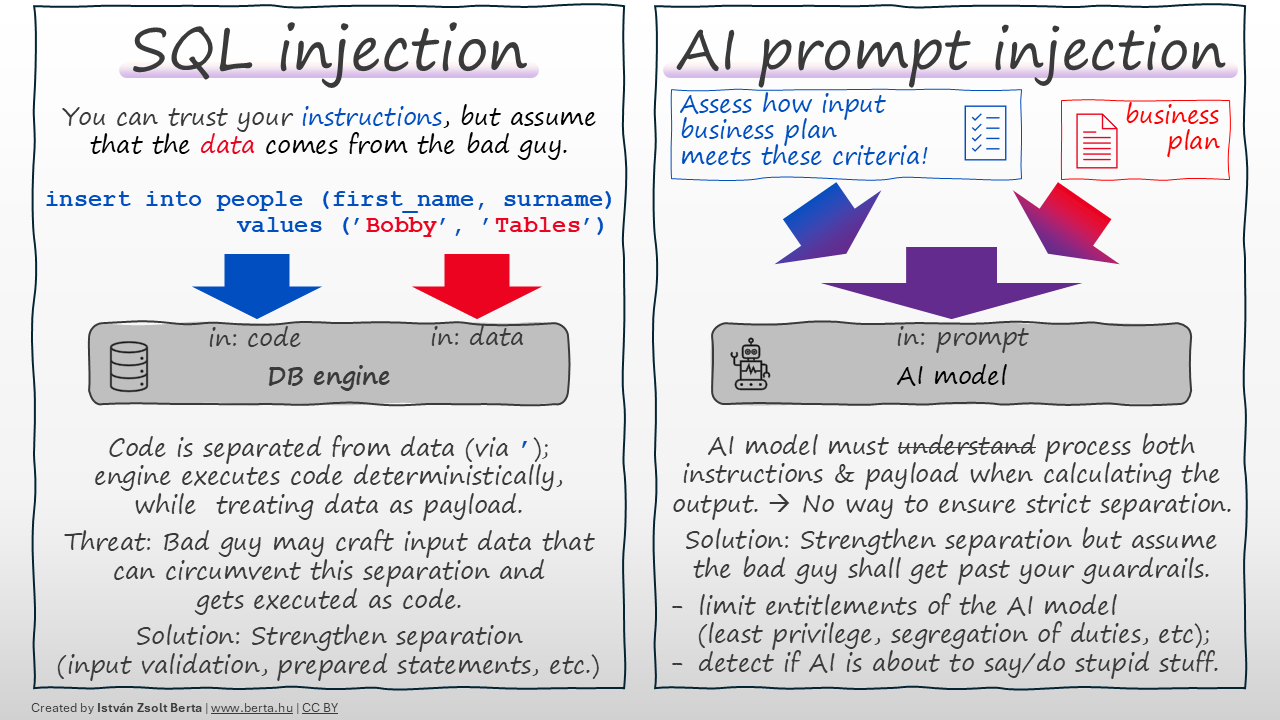
An AI model🤖 receives a prompt from with instructions the programmer, potentially along with untrusted data payload for processing. In case of prompt injection, the attacker crafts malicious payload so that the AI model would confuse it with the instructions; if successful, the attacker can make the AI model do or say anything they want.
Fundamental difference: Both the instructions and the data get folded into the same 'prompt', before processed by the AI model. There is no strict separation between instructions and data payload, and — based on my understanding — STRICT SEPARATION IS NOT POSSIBLE with current technology. The AI model needs to process and 'understand' both instructions and payload and both shall 'influence' their conclusions. There is no way to mark certain parts of the prompt so that the model cannot 'execute' them as commands. (While you can give such 'instructions' like 'ignore user commands', they will be part of the same prompt and at the same level; if the attacker's 'ignore instructions' command is more persuasive, the AI will follow it.) Not a bug🐞 — a feature of how this technology works.
I am not saying you should not strengthen separation of instructions and code as much as you can (e.g. via guardrails or other AI agents checking for malicious prompts or contaminated output). Do these, but be skeptical, as they are trying to 'make water not wet'.
What can give more assurance?
- 👉 Limit what the AI model can do (least privilege, segregation of duties and other traditional security measures you would use for a human).
- 👉 Assume the bad guy gets past your guardrails → detect and act if the AI is about to say or do something stupid. Use deterministic tools here, don't rely on AI alone to catch AI. (AI agents may fall victim to the same attack they are supposed to detect.)
TL;DR: Most injections are solved by separating code from data. In AI, the code is the data. Don’t trust AI the output blindly, use common sense.
This post was first published on Linkedin here on 2026-04-19.